General:
- routing protocol for ISO CLNP (Connectionless Network Protocol)
- NET (Network Entity Title) required by configuration (L3 address) Has different formats. One practical is below:
Area (1-13 bytes)| System ID (6 bytes) | Selector (1 byte) (eg. 47.000|1921.6810.0001|00)
Selector is 00 in a NET. The NET must begin with one octet (eg 47) and end with one octed (00)
Selector is non 00, the address is NSAP (Network Service Access Point)
NSAP describes a service attachment at the network layer (similar to IP protocol at the IP layer)
- operates over Ethernet 802.2 LLC (not over the common Ethernet II)
- dual ISIS (RFC1195) supports CLNS and IP
- hierarchical with 2 level hierarchy (L2 - core)
- ignores TLVs it does not understand
Adjacencies:
- L1 area ID must be the same
Showing posts with label Networking. Show all posts
Showing posts with label Networking. Show all posts
BGP notes
Neighbor states:
Idle: all connections are refused
Connect: wait for TCP to establish
Active: initiates the TCP connections
OpenSent: Local waits for Open message from peer. After receiving open, if no errors BGP sends keepalive
OpenConfirm: BGP waits for keepalive or notification
Established: Can exchange update, notification and keepalive
Message types:
Open: sent when TCP 3way is complete. Initiates the BGP session and contains details about BGP neighbor and supported and negotiated potions
Update: Transports routing information between BGP peers
Keepalive: On BGP level. Contains the BGP header and has no data.
Notification: sent when something is wrong (eg. unsupported options in the open message, hold time expires)
Refresh: BGP does not readvertise sent routes by default. Route refresh supports soft clearing of BGP sessions by allowing routes already sent to be re-advertised
BGP attributes:
- contained in the Update message, describes the prefixes in the message
- used to influence route selection and select best path
Local preference:
- exchanged by IBGP peers only
- used to set the exit path from the local AS
Idle: all connections are refused
Connect: wait for TCP to establish
Active: initiates the TCP connections
OpenSent: Local waits for Open message from peer. After receiving open, if no errors BGP sends keepalive
OpenConfirm: BGP waits for keepalive or notification
Established: Can exchange update, notification and keepalive
Message types:
Open: sent when TCP 3way is complete. Initiates the BGP session and contains details about BGP neighbor and supported and negotiated potions
Update: Transports routing information between BGP peers
Keepalive: On BGP level. Contains the BGP header and has no data.
Notification: sent when something is wrong (eg. unsupported options in the open message, hold time expires)
Refresh: BGP does not readvertise sent routes by default. Route refresh supports soft clearing of BGP sessions by allowing routes already sent to be re-advertised
BGP attributes:
- contained in the Update message, describes the prefixes in the message
- used to influence route selection and select best path
Local preference:
- exchanged by IBGP peers only
- used to set the exit path from the local AS
OSPF notes
Packet types:
Hello (type1): used to discover neighbors, build and maintain adjacencies
DBD(type2): database description packets. These are a summary of the topological database. Detects MTU mismatches (fragmentation is not allowed). Have bits I (start of DBD), M (more ackets DB), MS(master/slave used to decides who starts sending DBD first)
LSR(type3): link state request. Request specific link state advertisement (LSA) from a neighbor, typically after receiving DBD packets and noticing the local link state database is out of date
LSU(type4): link state updates. Advertises LSAs into the network . Can contain multiple LSAs
LSAck(type5): link state acknowledgements. Acknowledges LSUs
Packet formats:
OSPF packet:
Version | Type | Length | Router ID | Area ID | Cksum | Auth type | Auth data | Data
LSU packet (type 4):
Number of LSAs | LSA header | LSA data | LSA header | LSA data | ...
LSA header:
Age | Options | Link-state Type | Link-state ID | Advertising router | Seq number | Cksum | Length
LSA types:
Router LSA (type 1):
- has area scope
- describes local router
- standards LSA header plus some extras (only a few showed below):
- 5 bits set to 0 followed by bits 6,7,8 set for virtual links (V), ASBR (E), ABR (B)
- number of links (2 bytes)
- link ID (4 bytes)
- link data (4 bytes)
- link type (1 bytes)
- metric (2 bytes)
Link-type: Type 1 (P2P). Link ID: Neighbor Router ID. Link data: Local interface IP
Link-type: Type 2 (Transit). Link ID: DR's interface IP. Link data: Local interface IP [broadcast segment]
Link-type: Type 3 (Stub). Link ID: Network number. Link data: Subnet mask [passive interfaces, loopback interfaces]
Link-type: Type 4 (Virtual link). Link ID: Neighbor Router ID. Link data: Local interface IP
Hello (type1): used to discover neighbors, build and maintain adjacencies
DBD(type2): database description packets. These are a summary of the topological database. Detects MTU mismatches (fragmentation is not allowed). Have bits I (start of DBD), M (more ackets DB), MS(master/slave used to decides who starts sending DBD first)
LSR(type3): link state request. Request specific link state advertisement (LSA) from a neighbor, typically after receiving DBD packets and noticing the local link state database is out of date
LSU(type4): link state updates. Advertises LSAs into the network . Can contain multiple LSAs
LSAck(type5): link state acknowledgements. Acknowledges LSUs
Packet formats:
OSPF packet:
Version | Type | Length | Router ID | Area ID | Cksum | Auth type | Auth data | Data
LSU packet (type 4):
Number of LSAs | LSA header | LSA data | LSA header | LSA data | ...
LSA header:
Age | Options | Link-state Type | Link-state ID | Advertising router | Seq number | Cksum | Length
LSA types:
Router LSA (type 1):
- has area scope
- describes local router
- standards LSA header plus some extras (only a few showed below):
- 5 bits set to 0 followed by bits 6,7,8 set for virtual links (V), ASBR (E), ABR (B)
- number of links (2 bytes)
- link ID (4 bytes)
- link data (4 bytes)
- link type (1 bytes)
- metric (2 bytes)
Link-type: Type 1 (P2P). Link ID: Neighbor Router ID. Link data: Local interface IP
Link-type: Type 2 (Transit). Link ID: DR's interface IP. Link data: Local interface IP [broadcast segment]
Link-type: Type 3 (Stub). Link ID: Network number. Link data: Subnet mask [passive interfaces, loopback interfaces]
Link-type: Type 4 (Virtual link). Link ID: Neighbor Router ID. Link data: Local interface IP
ssh tunnels set up and port forwarding
SSH tunnels allow you to forward a local TCP port to a remote machine and vice versa. The tunnel option is available in many ssh clients. I will give the example here on how to create SSH tunnels with putty and the openssh-client.
I will consider in the below that we want to access the SERVER on port 80 (http server).

SSH tunnel is set up on the CLIENT:
The tunnel configuration is done under Connection - SSH - Tunnels. Source port is the local port, destination is where the connection will be forwarded after exiting the SSH tunnel.
After you specify source port and destination, you need to click "Add" for the configuration to take effect.
If you want to access the remote server from other hosts, make sure you check the box "Local ports accept connections from other hosts", otherwise the port 2000 will be opened only for the loopback address (127.0.0.1)
I will consider in the below that we want to access the SERVER on port 80 (http server).
Scenario 1. SSH tunnel setup with local port forwarding.

The SSH tunnel is shown with the red arrow. In order to access the SERVER through the ssh tunnel the connection will have to be made on the CLIENT's local forwarded port (2000 in the example). The traffic between the CLIENT and SSH-HELPER is encrypted by ssh, the traffic between the SSH-HELPER and the SERVER is not encrypted.
SSH tunnel is set up on the CLIENT:
openssh-client:
ssh -L *:2000:server:80 ssh-helper
The '*' before the local port to be forwarded 2000 denotes that the port 2000 should be listening on all available interfaces on the client. This goes according to the openssh-client configuration.
putty:
The tunnel configuration is done under Connection - SSH - Tunnels. Source port is the local port, destination is where the connection will be forwarded after exiting the SSH tunnel.
After you specify source port and destination, you need to click "Add" for the configuration to take effect.
If you want to access the remote server from other hosts, make sure you check the box "Local ports accept connections from other hosts", otherwise the port 2000 will be opened only for the loopback address (127.0.0.1)
How to identify top traffic speakers with wireshark conversations
Among other very useful and interesting things that wireshark can show in a packet capture, it can also display the top traffic conversations based on various criteria such as IP addresses, L2 ethernet addresses, IPv6 address or L4 information.
The conversation list is available from the Statistics -> Conversations menu.
Below an example taken showing the top bps rate (B->A direction) for the TCP protocol, where A and B are the endpoints identified by IP and TCP port number
Replaying packets with tcpreplay
Tcpreplay is a suite of tools that allows editing and replaying previously captured traffic in libpcap format. This can come handy in many situations, one common use is traffic pattern based behavior re-creation in a lab environment.
Tcpreplay suite comes with the following tools:
Tcpreplay suite comes with the following tools:
- tcpprep - multi-pass pcap file pre-processor which determines packets as client or server and creates cache files used by tcpreplay and tcprewrite
- tcprewrite - pcap file editor which rewrites TCP/IP and Layer 2 packet headers
- tcpreplay - replays pcap files at arbitrary speeds onto the network
- tcpliveplay - Replays network traffic stored in a pcap file on live networks using new TCP connections
- tcpreplay-edit - replays; edits pcap files at arbitrary speeds onto the network
- tcpbridge - bridge two network segments with the power of tcprewrite
- tcpcapinfo - raw pcap file decoder and debugger
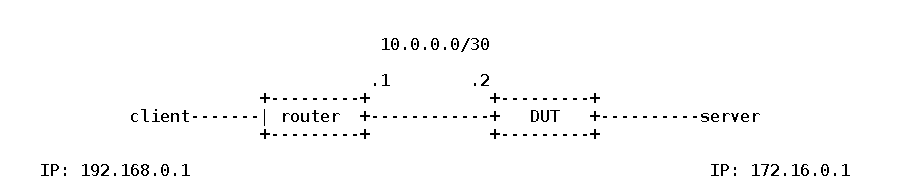
Now in this setup we're interested in how our DUT device (Device Under Test) is reacting given a specific traffic pattern that is let's say very specific to this environment. I will assume the DUT is a Layer 3 device.
How to delete files from CSS11501
The scope of this post is to show how to delete archived files on a Cisco CSS11501. In order to delete other files (core dumps, logs, etc) the procedure is similar, you just need to know what you want to delete.
In order to manipulate the files we need to go to debug mode:
CSS11501# llama
CSS11501(debug)# ap_file delete c:/Archive/archived_rc_file
CSS11501(debug)# dir c:/Archive/
CSS11501(debug)#
Cisco CSS11501 source groups and ACL
Few days ago I had to reconfigure a running CSS 11501 loadbalancer from an existing configuration in which traffic initiated from some services running in one VLAN towards any destination was source NAT-ed to a selective NAT which was based on the destination IP address.
What I wanted to do is almost exactly to what is described in this official Cisco document with the difference that I had more IP destination addresses for my ACL based source NAT, I had only 2 VLANs and the IP addresses were different than in the example given.
Below is an excerpt similar to my original configuration:
Reference: CSS Content Load-Balancing Configuration Guide (Software Version 8.10)
What I wanted to do is almost exactly to what is described in this official Cisco document with the difference that I had more IP destination addresses for my ACL based source NAT, I had only 2 VLANs and the IP addresses were different than in the example given.
Below is an excerpt similar to my original configuration:
service SERV11
ip address 192.168.0.3
protocol tcp
keepalive type tcp
redundant-index 111
keepalive port 11501
active
service SERV12
ip address 192.168.0.4
protocol tcp
keepalive type tcp
redundant-index 112
keepalive port 11501
active
....
owner OWNER1
content SERV_BAL
vip address 10.0.0.1
add service SERV11
add service SERV12
redundant-index 11
balance leastconn
flow-reset-reject
flow-timeout-multiplier 20
active
....
group GROUP1
add service SERV11
add service SERV12
vip address 10.0.0.1
redundant-index 21
active
acl enable
....
acl 1
clause 5 bypass any 192.168.0.3 255.255.255.255 destination 10.0.0.11 255.255.255.255
clause 10 bypass any 192.168.0.3 255.255.255.255 destination 10.0.0.12 255.255.255.255
clause 15 bypass any 192.168.0.4 255.255.255.255 destination 10.0.0.11 255.255.255.255
clause 20 bypass any 192.168.0.4 255.255.255.255 destination 10.0.0.12 255.255.255.255
clause 101 permit any 192.168.0.3 255.255.255.255 destination any sourcegroup GROUP1
clause 102 permit any 192.168.0.4 255.255.255.255 destination any sourcegroup GROUP1
clause 254 permit any any destination any
apply circuit-(VLAN1)
acl enable
....
service SERV11
ip address 192.168.0.3
protocol tcp
keepalive type tcp
redundant-index 111
keepalive port 11501
active
service SERV12
ip address 192.168.0.4
protocol tcp
keepalive type tcp
redundant-index 112
keepalive port 11501
active
....
owner OWNER1
content SERV_BAL
vip address 10.0.0.1
add service SERV11
add service SERV12
redundant-index 11
balance leastconn
flow-reset-reject
flow-timeout-multiplier 20
active
....
group GROUP1
vip address 10.0.0.1
redundant-index 21
active
....
acl 1
clause 5 bypass any 192.168.0.3 255.255.255.255 destination 10.0.0.11 255.255.255.255
clause 10 bypass any 192.168.0.3 255.255.255.255 destination 10.0.0.12 255.255.255.255
clause 15 bypass any 192.168.0.4 255.255.255.255 destination 10.0.0.11 255.255.255.255
clause 20 bypass any 192.168.0.4 255.255.255.255 destination 10.0.0.12 255.255.255.255
clause 101 permit any 192.168.0.3 255.255.255.255 destination any sourcegroup GROUP1
clause 102 permit any 192.168.0.4 255.255.255.255 destination any sourcegroup GROUP1
clause 254 permit any any destination any
apply circuit-(VLAN1)
acl 2
clause 254 permit any any destination any
apply circuit-(VLAN2)
Reference: CSS Content Load-Balancing Configuration Guide (Software Version 8.10)
VRRP master/master issue on CSS 11501 with 3550

In the picture illustrated in which two Cisco CSS 11501 Loadbalancers were providing a redundant setup with fate sharing, the route from the "Servers" networks towards the client network was provided through an IP setup on a redundant interface shared by the 2 Loadbalancers.
The VRRP announcements for the virtual routers holding redundant interfaces on vlans A,B between the two loadbalancers were going through the 2 Cisco 3550 Catalyst switches which were running (C3550-I9Q3L2-M), Version 12.1(19)EA1c IOS.
To better depict the picture, each of the 2 Loadbalancers had one physical link to its corresponding L3 3550 and carrying over it vlans A,B (on the server side), one ISC link was connecting the two CSS for adaptive session redundancy (ASR) and the link between the two Cisco 3550 was set up as 802.1q trunk and transporting among other the vlans A,B over which the VRRP communication had to take place.
Although the setup and configuration was double and triple checked, the problem was that each of the Loadbalancers was claiming to be master on the virtual router instance running for its corresponding vlan (A or B).
For brevity I will illustrate the case of the virtual router on vlan A, although the problem seemed to be strongly related to the fact that the CSS were connecting through a trunk link to the 3550.
CSS11510_right# show redundant-interfaces
Redundant-Interfaces:
Interface Address: 192.168.0.2 VRID: 1
Redundant Address: 192.168.0.1 Range: 1
State: Master Master IP: 192.168.0.2
CSS11501_left# show redundant-interfaces
Redundant-Interfaces:
Interface Address: 192.168.0.3 VRID: 1
Redundant Address: 192.168.0.1 Range: 1
State: Master Master IP: 192.168.0.3
Checking the counter for VRRP announcements received by the presumably slave Loadbalancer at some point in time, the number was always 0.
CSS11501_left# llama
CSS11501_left(debug)# ip scp statistics
totalIpFrames received: 211300
invalidIPFrame: 0 malformedIPFrame: 0
noIngressIPFrame: 0 srcDestSameIPFrame: 0
badIPVersion: 0 badIpHeaderLength: 0
badIpChecksum: 0 badSrcIPFrame: 0
loopbackIPFrame: 0 badIPAddress: 0
badIpDestAddress: 0 zeroTTLIPFrame: 0
badIpProtocol: 0 badIpOptions: 0
Packets received with supported protocol types:
IPPROTO_IP: 0 IPPROTO_ICMP: 12285
IPPROTO_IGMP: 0 IPPROTO_GGP: 0
IPPROTO_TCP: 3129 IPPROTO_EGP: 0
IPPROTO_PUP: 0 IPPROTO_UDP: 47625
IPPROTO_IDP: 0 IPPROTO_TP: 0
IPPROTO_EON: 0 IPPROTO_OSPF: 0
IPPROTO_ENCAP: 0 IPPROTO_VRRP: 0
IPPROTO_OSPF: 0
IP PACKET TO VXWORKS STATISTICS:
packetLeakToVxWorks: 170436
I didn't solve the issue myself. I was notified that there is a problem with the current IOS running on the 3550 and there was a need to upgrade to at least an EMI image 12.1.20. There is also a bug logged with Cisco, although the setup and the configuration of the presented issue and the one logged with Cisco are not exactly the same.
Here is the bug logged to Cisco.
After upgrading to 12.1.20 IOS, the VRRP announcements were received by the slave Loadbalancer and the initial VRRP negotiation took place correctly.
Reference: CSS Redundancy Configuration Guide
Cisco CSS 11500 series internal services
By default the Cisco CSS 11501 series loadbalancers will create an implicit internal service to check the availability of the gateways for its static defined routes.
This internal service monitors the availability of the route which goes through a specific gateway by sending ICMP keepalives to that gateway. In that way if the internal service is in "Alive" state, the route for which the internal service is running is maintained in the routing table, otherwise if the service is in "Down" state then the route is withdrawn from the routing table (if there are no valid arp entries cached for that gateway).
The checking of the service availability is implemented through ICMP keepalives (ping) which are sent to the gateway of the destination defined in the static route.
These services are visible from the debug mode of the CSS. To have a look how they are defined and at which interval the keepalives are sent you can use:
CSS11501# llama
which gets you to debug mode
This internal service monitors the availability of the route which goes through a specific gateway by sending ICMP keepalives to that gateway. In that way if the internal service is in "Alive" state, the route for which the internal service is running is maintained in the routing table, otherwise if the service is in "Down" state then the route is withdrawn from the routing table (if there are no valid arp entries cached for that gateway).
The checking of the service availability is implemented through ICMP keepalives (ping) which are sent to the gateway of the destination defined in the static route.
These services are visible from the debug mode of the CSS. To have a look how they are defined and at which interval the keepalives are sent you can use:
CSS11501# llama
which gets you to debug mode
Recovering err-disabled ports on Cisco Catalysts IOS platforms
By default, Catalyst switches detect errors that occur on switch ports.
If the errors are serious it can take the action to shut down the switch port until someone will manually enable it or until a
predefined period of time has elapsed. This happens in order to avoid for example unwanted or faulty connections on the switch port.
Serious errors causes include (but are not limited to):
bpduguard — Detects when a Spanning Tree bridge protocol data unit (BPDU) is received on a port configured for STP portfast
link-flap — Detects when the port link state is “flapping” between the up and down states
pagp-flap — Detects when an EtherChannel bundle’s ports no longer have consistent configurations
rootguard — Detects when an STP BPDU is received from the root bridge on an unexpected port
For a complete list of errdisable causes go here.
If you decide that some of the error are not serious enough, you can tune the switch to trigger a port being disabled only for some causes.
Type in global configuration mode:
If the errors are serious it can take the action to shut down the switch port until someone will manually enable it or until a
predefined period of time has elapsed. This happens in order to avoid for example unwanted or faulty connections on the switch port.
Serious errors causes include (but are not limited to):
bpduguard — Detects when a Spanning Tree bridge protocol data unit (BPDU) is received on a port configured for STP portfast
link-flap — Detects when the port link state is “flapping” between the up and down states
pagp-flap — Detects when an EtherChannel bundle’s ports no longer have consistent configurations
rootguard — Detects when an STP BPDU is received from the root bridge on an unexpected port
For a complete list of errdisable causes go here.
If you decide that some of the error are not serious enough, you can tune the switch to trigger a port being disabled only for some causes.
Type in global configuration mode:
Switch(config)# errdisable detect cause [all | cause-name]
Switch# show interface status
..........
Port Name Status Vlan Duplex Speed Type
Fa0/1 err-disabled 5 full 100 100BaseTX
..........
NAT & IP forwarding on Linux gateway
Suppose we have only one publicly routable IP address assigned by our ISP and we want to be able to connect from the computers located in our internal LAN to the internet. Using private IP addresses is a common way to access the internet and internal shared resources
For the ease of explanation/understanding we’ll add some details in our scenario.
eth0 – the network interface card (NIC) connected to the ISP net
eth1 – the NIC connected to the internal LAN
As for the gateway there are some basic requirements:
- we’ll need at least 2 network interface cards (one/more connected to the internal LAN switch/hub, one/more connected to your ISP provider net) supported by your kernel
- support for networking, iptables and NAT in the kernel (for default 2.6/ 2.4 kernels on major Linux distributions this is enabled by default)
- enable IP forwarding (disabled by default on modern Linux distribution). To enable IP forwarding there are several ways to accomplish this. The common accepted method is through sysctl
Run the following command as root:
For the ease of explanation/understanding we’ll add some details in our scenario.
eth0 – the network interface card (NIC) connected to the ISP net
eth1 – the NIC connected to the internal LAN
As for the gateway there are some basic requirements:
- we’ll need at least 2 network interface cards (one/more connected to the internal LAN switch/hub, one/more connected to your ISP provider net) supported by your kernel
- support for networking, iptables and NAT in the kernel (for default 2.6/ 2.4 kernels on major Linux distributions this is enabled by default)
- enable IP forwarding (disabled by default on modern Linux distribution). To enable IP forwarding there are several ways to accomplish this. The common accepted method is through sysctl
Run the following command as root:
sysctl -w net.ipv4.ip_forward = 1
net.ipv4.ip_forward = 1
sysctl -p /etc/sysctl.conf
iptables -t nat -A POSTROUTING -o eth0 -j MASQUERADE
Duplex mismatches 100BASE-TX
I encountered a situation a few days ago where the two devices were not correctly negotiating the duplex setting. One box was a Cisco 2950 switch, the other was a Linux machine.
Although the ehternet interfaces of the 2 boxes were both capable of 100BASE-TX (full duplex) it was clear that the Linux machine's eth1 was running in half duplex mode
A tool on Linux which can display/change an ethernet card setting is ethtool.
Now for a bit of theory:
The link speed is determined by electrical signaling, so that either end of a link can determine what
the other end is trying to use. If both ends of the link are configured to autonegotiate, they will use
the highest speed that is common to them.
A link’s duplex mode, however, is negotiated through an exchange of information. This means that
for one end to successfully autonegotiate the duplex mode, the other end must also be set to autonegotiate.
Otherwise, one end will never see any duplex information from the other end and won’t
determine the correct common mode.
Although the ehternet interfaces of the 2 boxes were both capable of 100BASE-TX (full duplex) it was clear that the Linux machine's eth1 was running in half duplex mode
A tool on Linux which can display/change an ethernet card setting is ethtool.
Now for a bit of theory:
The link speed is determined by electrical signaling, so that either end of a link can determine what
the other end is trying to use. If both ends of the link are configured to autonegotiate, they will use
the highest speed that is common to them.
A link’s duplex mode, however, is negotiated through an exchange of information. This means that
for one end to successfully autonegotiate the duplex mode, the other end must also be set to autonegotiate.
Otherwise, one end will never see any duplex information from the other end and won’t
determine the correct common mode.
Subscribe to:
Posts (Atom)